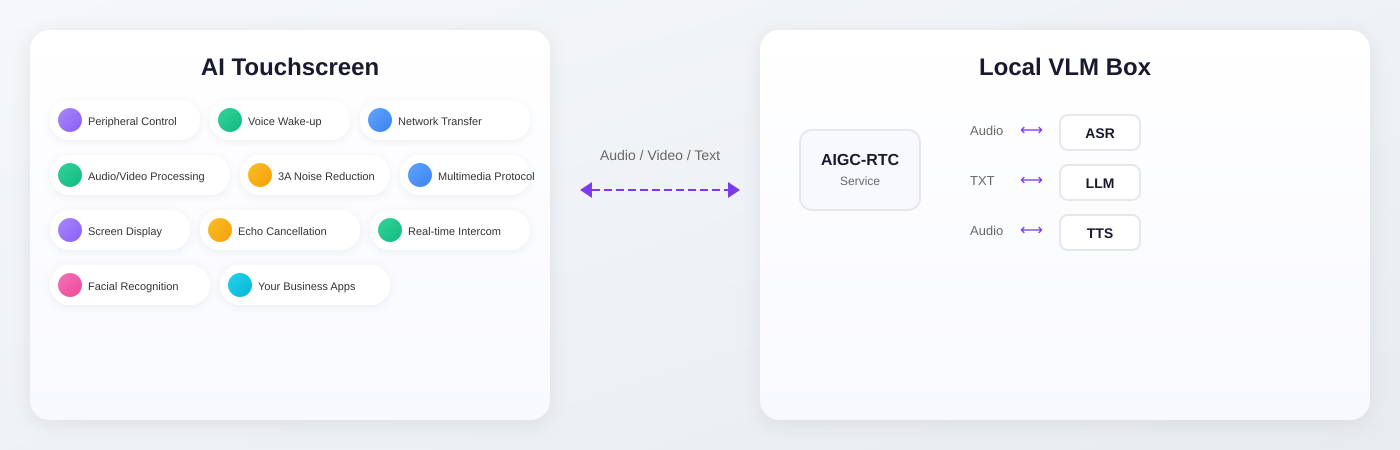
Local vision-language model Expansion Ready Cost-effective
Next-gen Touchscreens
With Edge AI
Intelligent touchscreens integrated with locally hosted VLM to achieve low-latency, high-privacy AIoT experience. Expansion Ready to fit your needs.
Built-in Camera
Steve recognized
Welcome home, Steve!
I see an active issue with garage door sensor.
"Resolve the garage door sensor issue"
Checking connection...
Calibrating sensor...
Updating firmware...
All done! Sensor fully functional.
Dealer X
AI agent with generated avatar
Request to VLM
Response from VLM